#DataSummitConference en #Berlin
Con un poco de retraso, os voy a contar lo que dio de si la conferencia de Hortonworks en Berlin, donde se hablo mucho del GDPR y de la nube.
Vuelo relampago y me plante en Berlin, 3 anos despues de irme de alli.
Recordar como era y todo lo vivido, fue una maravilla, amen de los 24 grados de temperatura! todo una delicia para poder moverse por ahi en bici.
Desgraciadamente, por otros motivos, me perdi casi la mitad del primer dia y pude llegar solo algunas confenrencias y keynotes que me fueran de interes. Las cosas de alto nivel las deje para mi colega de viaje, que para eso el es el arquitecto y yo solo me ocupo de hacer que sus cosas corran mejor y mas rapido en nuestras maquinas.
Primer dia
HDFS y S3
Hubo dos charlas que capturaron mi atencion, una sobre una propuesta de HDFS para poder conectar directamente el HDFS a el almacenamiento S3 de amazon, que si bien era muy tecnica, tenia grandes posibilidades.
Permite asignar una policy en HDFS que sea provided de manera que HDFS por debajo y asincronamente mueve los datos a S3 (HDFS-9806). Para que puede servir esto? eso mismo pregunto alguien (luego me di cuenta que era un de los de HortonWorks), pues para que Pig por ejemplo, que no permite usar almacenamiento que no sea HDFS local, te deje a usarlo.
Tambien viene bien como coldstorage
Speakers Thomas DeMoor y Ewan Higgs, los dos de Western Digita
Cloud & Operations
Esto fue mas que una charla, una Bird of a feather, un coloquio.
Basicamente, se hablo de una Cloudbreak de Hortonwork: te permite disenar, ejecutar, y administrar clusters en la nube de forma elastica:
- Configurar usando blueprints de Ambari lo que quieres
- Seleccionas el proveedor de Cloud
- Te provisiona el cluster
- Corre lo que tengas que corres
- Si te quedas corto de proceso, te amplia el cluster
- Cuando acaba, te mata el cluster
VTenia buena pinta
Segundo dia
Aqui hubo mas chicha, hasta las 11 no empezo lo que me gustaba, que era una charla de como estaba montado Hadoop y el entorno de BigData en el CERN, luego varias charlas sobre Hive con LLAP, un Crash course de Atlas, Ranger y la GDPR, otra de como de bien funciona LLAP en el cloud y un poco de networking.
Este dice, si que hice fotos, aqui os las pongo.
CERN
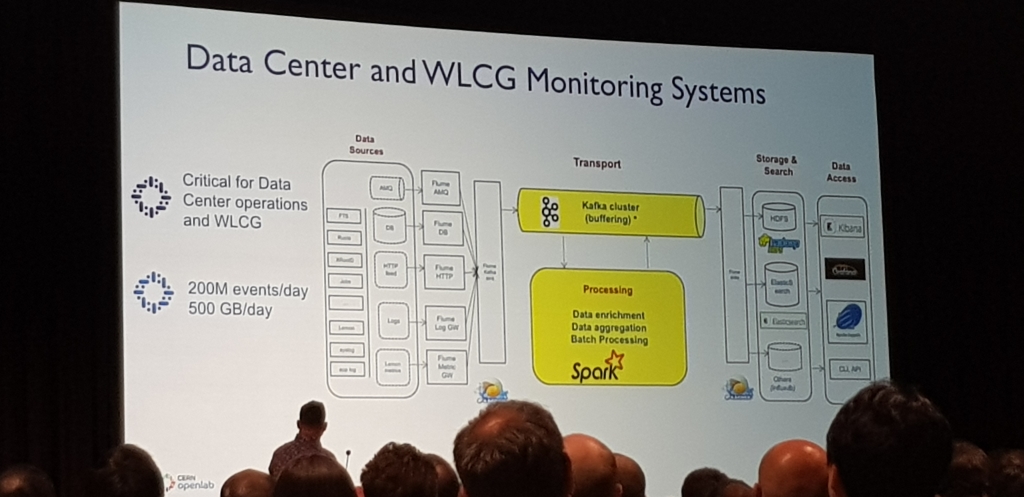
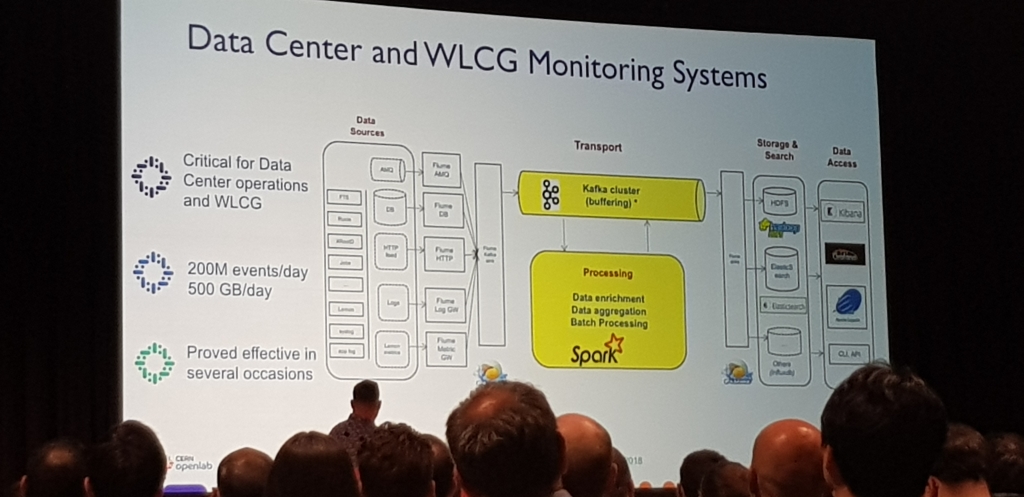
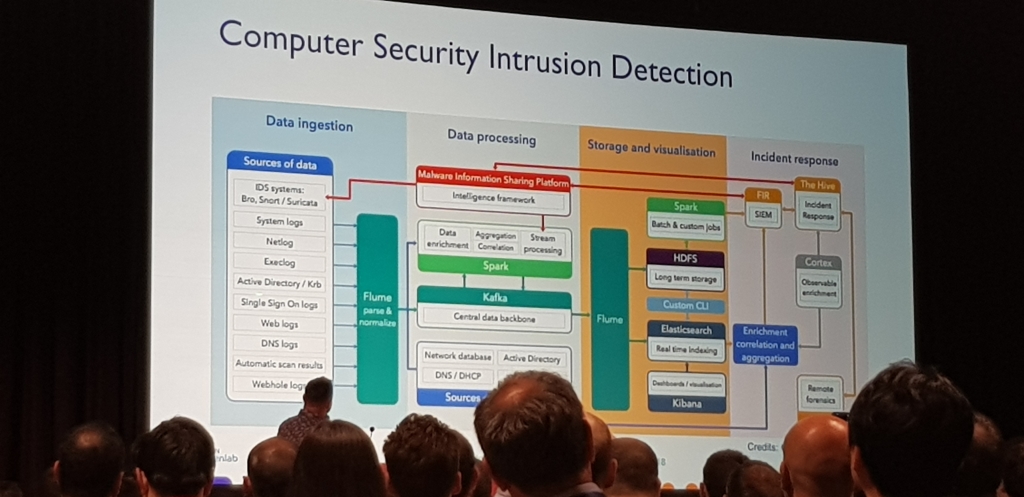
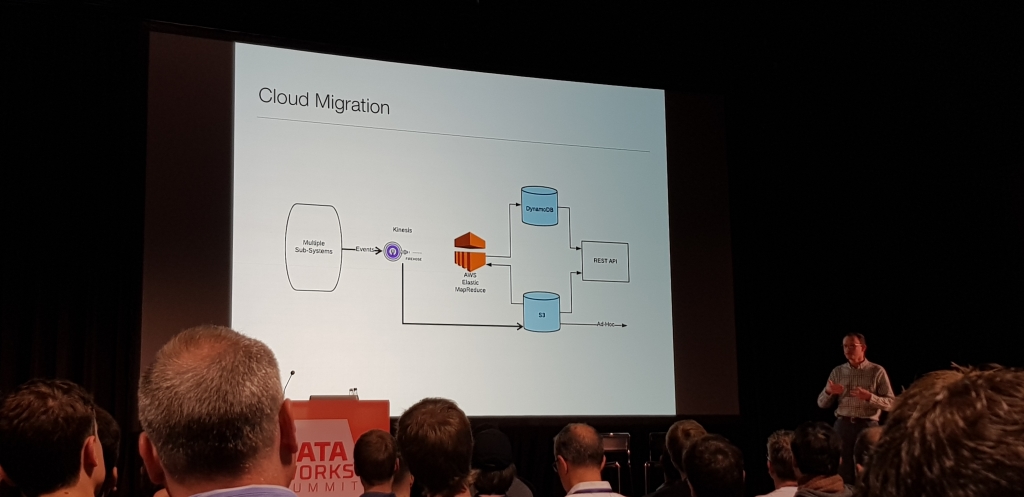
La sala estaba a reventar, basicamente conto como estaba montado todo en el CERN.
Lo que mas me dejo impactado, es que habian conseguido sacar de 1 PB de datos, 1 TB de informacion util en cada uno de los experimentos. Generaban aprox 500 GB de informacion diaria de la cual, mucho era ruido y tenian que filtrar.
La mejor y mas amena de las charlas, realmente mueven datos estos chicos del CERN ;)
Speaker > Evangelos Motesnitsalis


Hive LLAP: bueno en baremetal y bueno en el Cloud
Charla muy metodica de como en Disney, Chris Nauroth, haciendo pruebas metodicas con varios cores, usando prunning, threads, con LLAP y sin, etc. se dio cuenta de que LLAP y el sistema de cacheado que tiene, incluso levantado un cluster, ejecutando la consulta y matandolo, LLAP usaba esa cache y generaba una mejora del casi un 45%


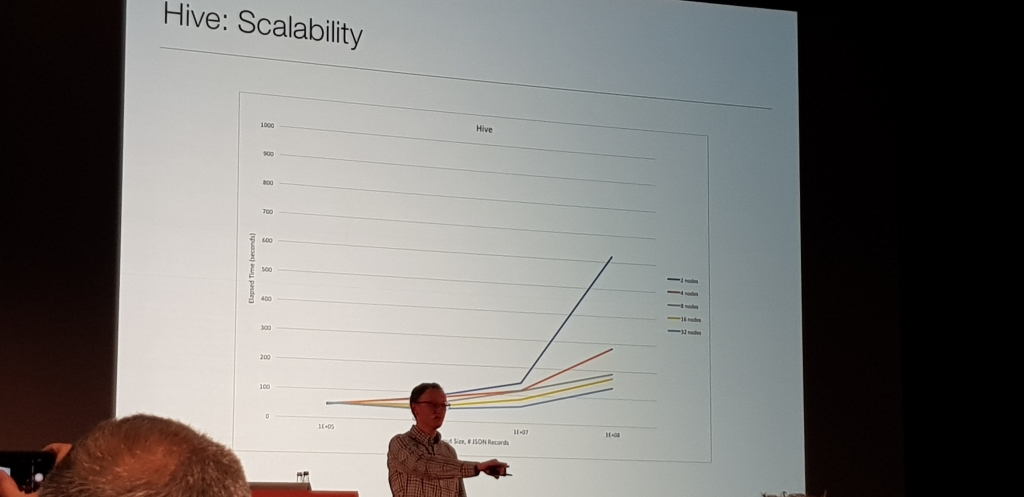
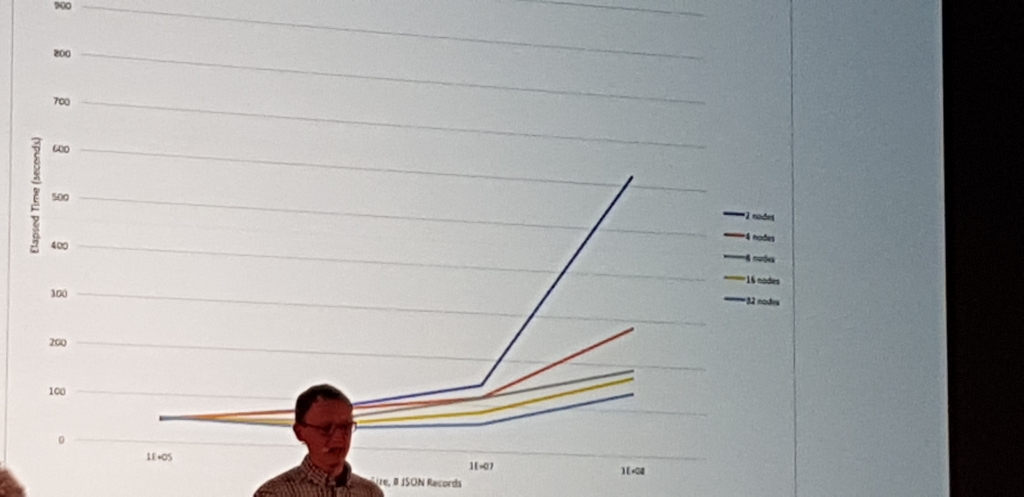
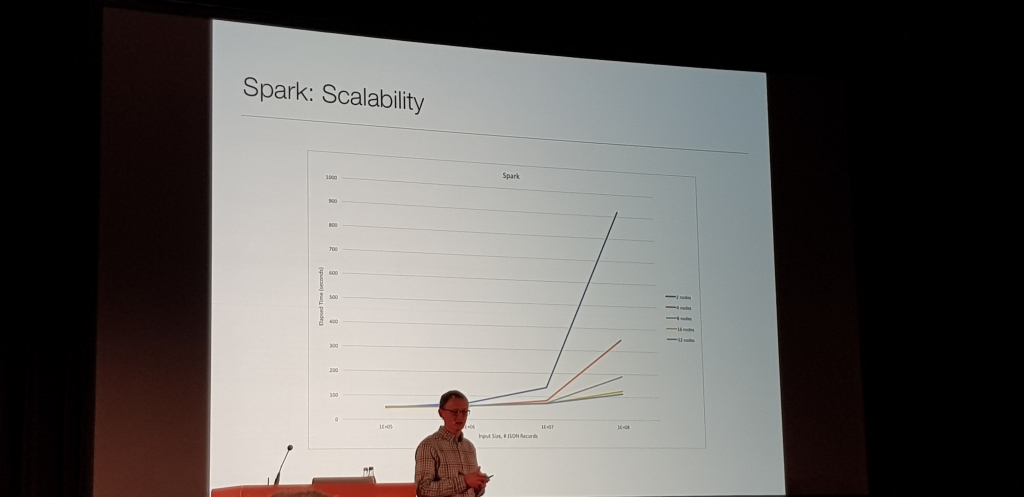
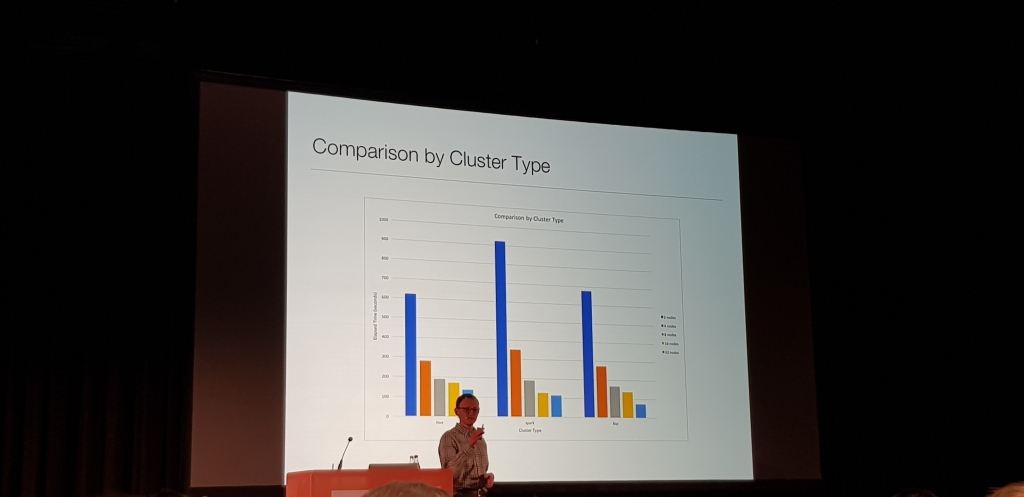


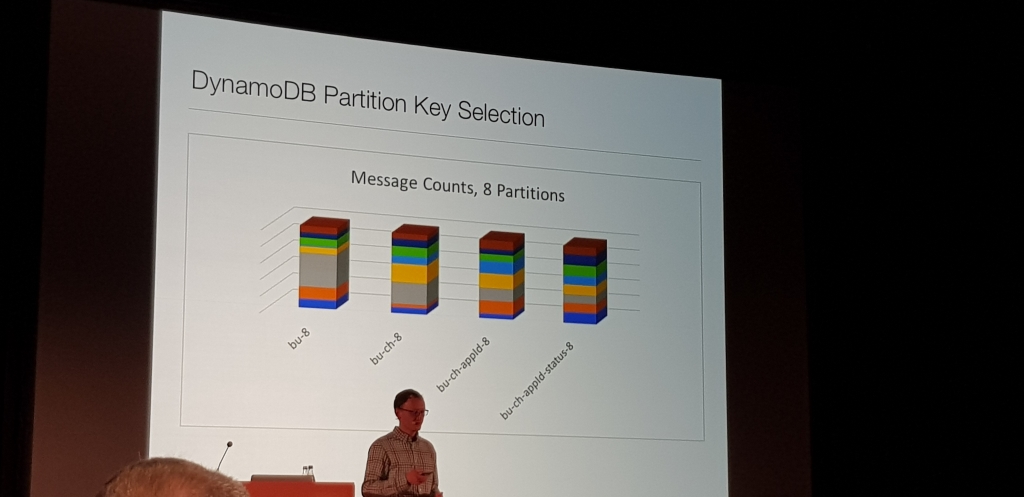
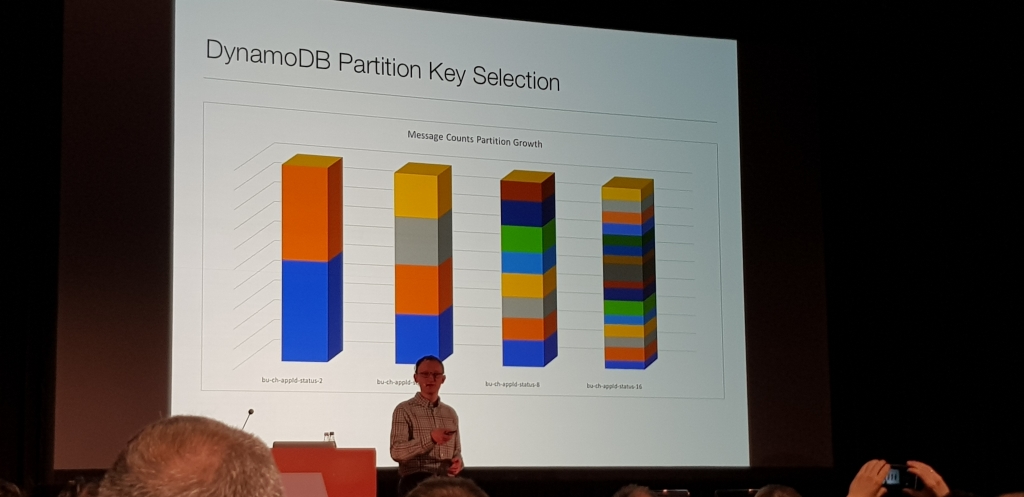
Sin Analiticas ETL con LLAP en Azure
A esta llegue tarde, pero el speaker, Ashish Thapliyal a traves de varios benchmarks, demostro que no hace falta realizar conversiones de ficheros CSV o JSON a archivos columnares para tener un buen rendimiento, es mas, con LLAP bien tuneado y corriendo sobre SSDs con almacenamiento Blob de Azure y sobre instancias normales, iba mejor en CSV que en ORC
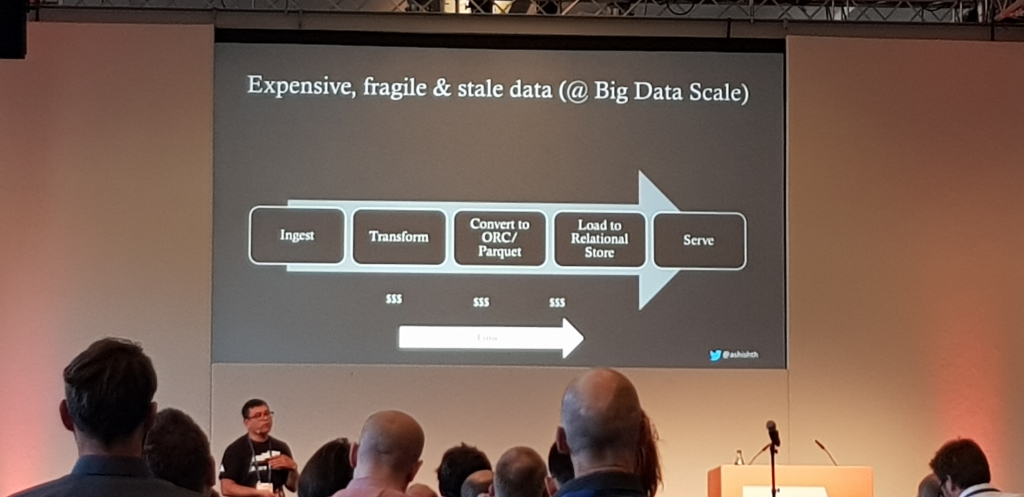

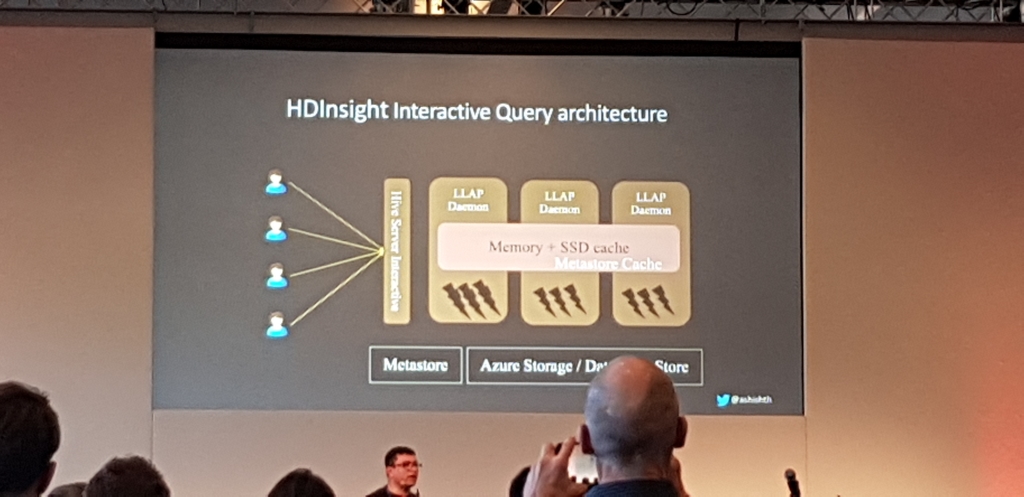


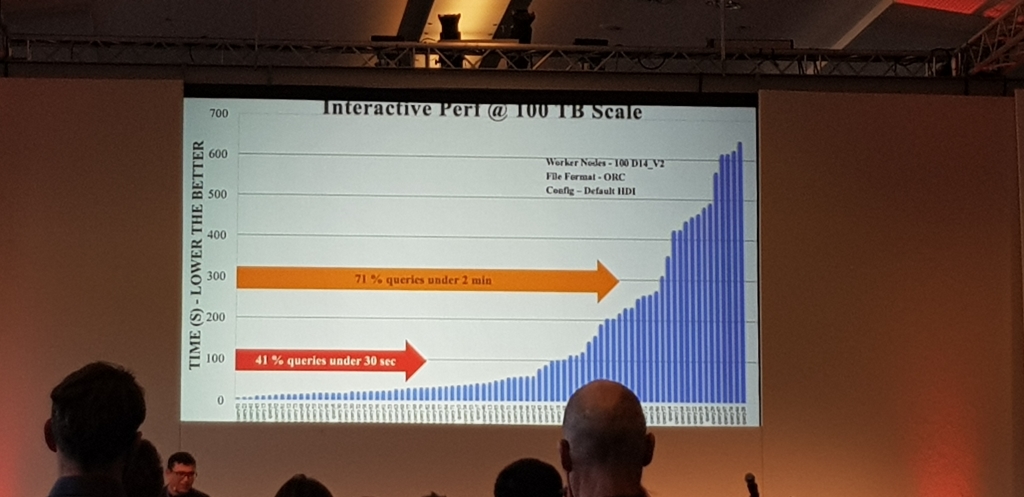
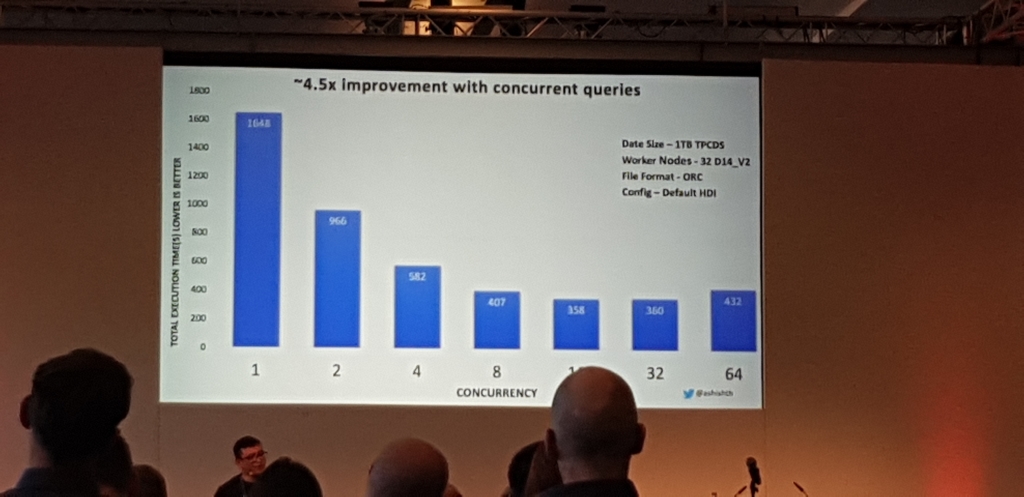

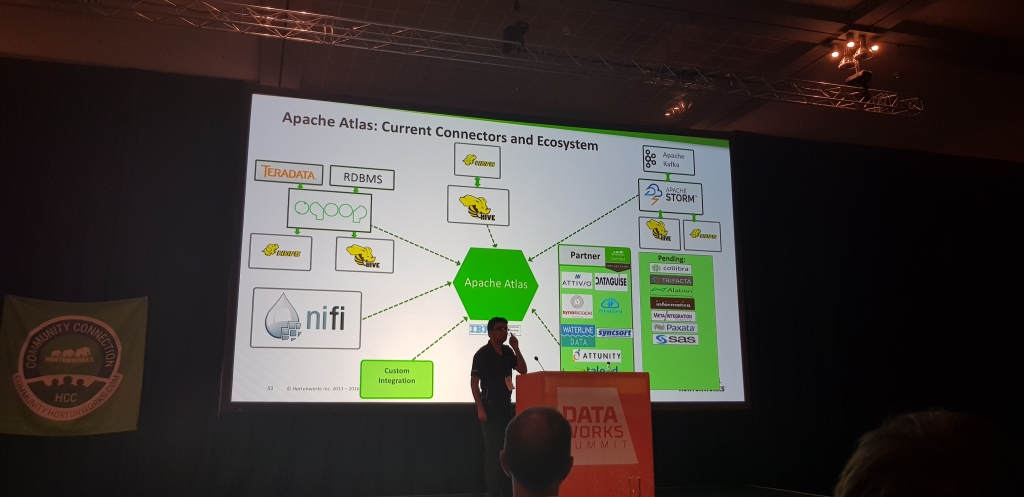
Atlas & Ranger y la GDPR
Este fue uno super interesante, con la reciente entraba en vigor de la GDPR, la governancia y soberania de los datos, se vuelve un tema crucial. En una encuesta que se hizo acerca de como de preparados estaban las empresas para afrontar la entrada en vigor el mes que viene de esta ley:
- 20% estaban preparados
- 40% no lo estaban
- 30% no lo estaban ni lo estarian
- restante: pero que cojones es la GDPR
En sintesis, Atlas permite el taggeo de las fuentes de datos de forma centralizada y sobretodo una standarizacion de el formato de los metadatos, como una forma de sentar de-facto un punto de partida opensource y no basado en versiones comerciales / propietarias.
Ranger necesita de Atlas para funcionar a toda pastilla, permite hacer enforcement de politicas de seguridad usando estos tags, de manera que se puede, por ejemplo:
- Que un usuario de EEUU no pueda acceder a los datos personales de los datos de clientes europeos
- Que un un analista no pueda acceder a datos fuera del horario de trabajo
- Que los numeros de tarjeta de credito o de identificacion nacional, sean enmascarados siguiendo patrones diferentes
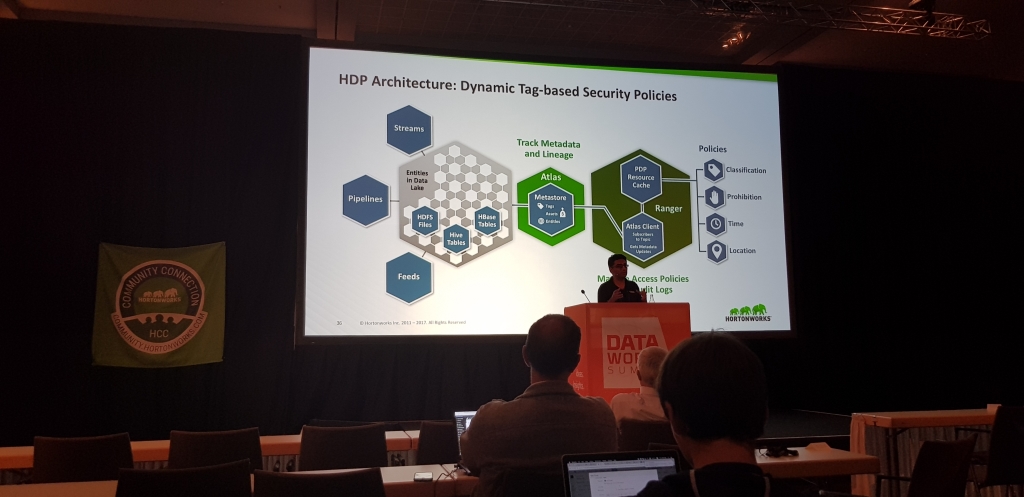


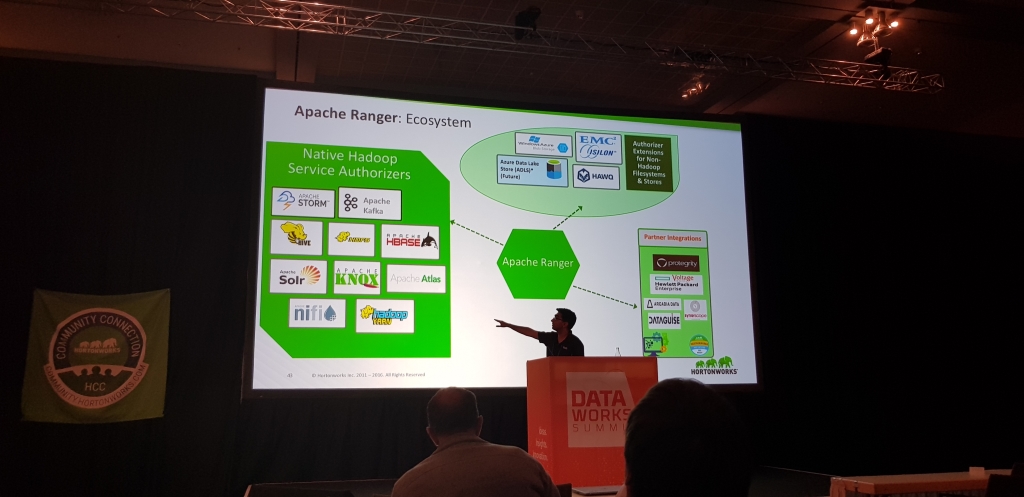

Conclusion
No me quiero enrrollar mucho porque me he prometido que lo haria corto. Vi una clara tendecia a correr todo en la nube. La nube es la eleccion de muchos de los responsables tecnicos de big data por la elasticidad que tiene.
Azure estuve muy presente (hasta tengo calcetines de ellos!) pero ni Google Cloud ni AWS aparecieron por ahi.
GDPR fue algo muy presente, con la entrada en vigor de la ley, todo el mundo necesita estar preparado y pocos o casi nadie lo esta, asi que vamos a tener meses divertidos TODOS, intentando estar preparados para la multas que te pueden caer.
Espero que el resumen os haya gustado, intentare poner todas las fotos y ponentes….
Hasta el que viene, #DWS18 !!!
PD: a ver si tengo suerte, y me mandan a la de Kafka en San Francisco en octubre de este 2018 ;)